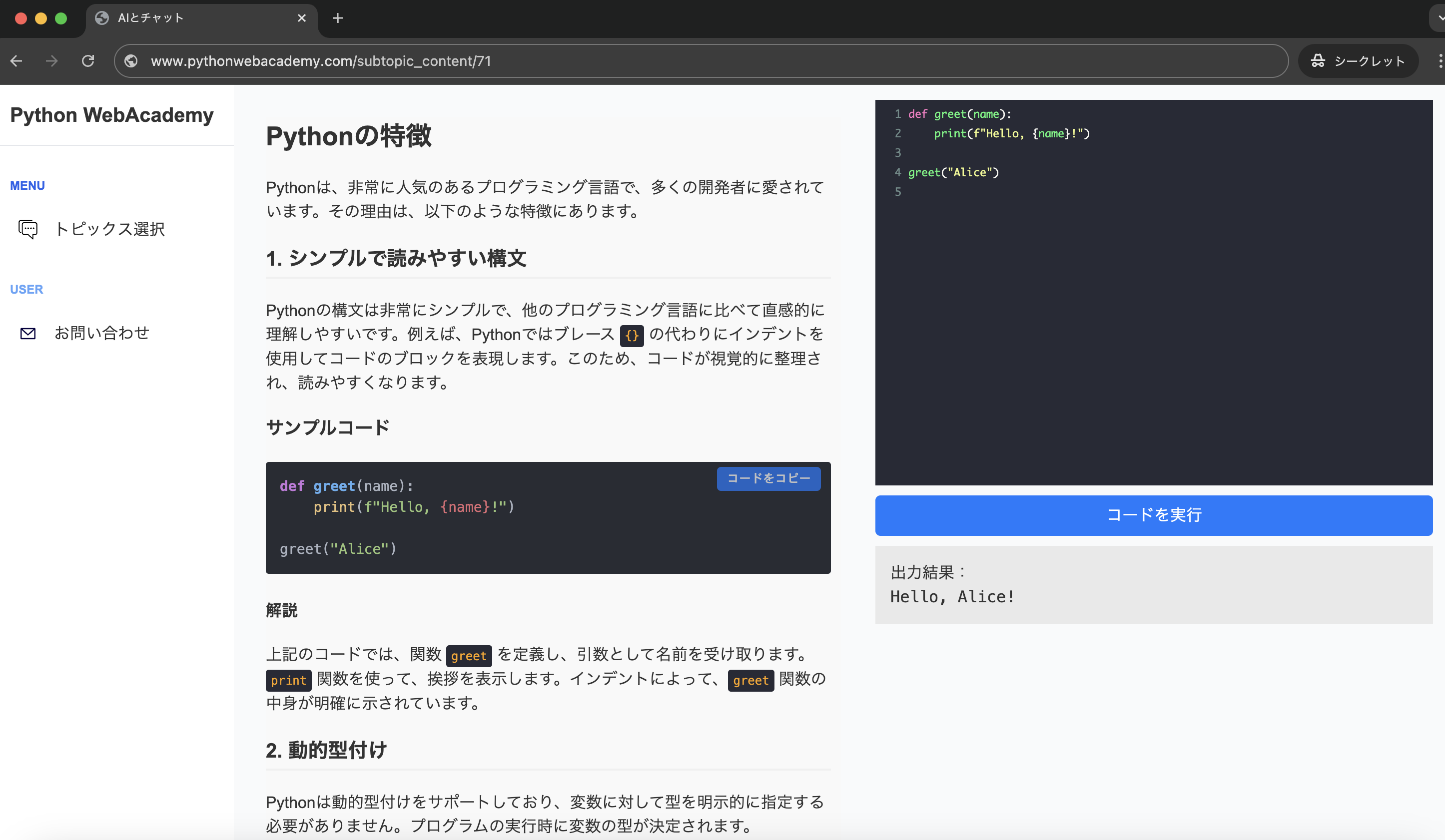
Pythonのリスト内包表記を使いこなせ!3行のループを1行にまとめる書き方

Pythonを学び始めてしばらく経つと、リストの中にデータを追加していく処理を何度も書くようになります。 空のリストを用意して、for文を回し、appendメソッドで要素を一つずつ追加していく。
この一連の流れは非常に基本的ですが、コードが長くなりがちで少し退屈に感じることはありませんか。 実はPythonには、この数行にわたる処理をたった1行で、しかもスマートに記述できる魔法のような記法が存在します。
それが、リスト内包表記です。 エンジニア歴10年の私が断言しますが、この記法をマスターすると、あなたのコードの見た目は驚くほど美しく、プロフェッショナルなものに変わります。
今回は、初心者の方がつまずきやすいポイントを丁寧に解消しながら、リスト内包表記の真髄を余すことなくお伝えします。 読み終わる頃には、あなたも「内包表記を使わないと落ち着かない」という感覚になっているかもしれません。
リスト内包表記とは何か?¶
リスト内包表記とは、既存のリストや範囲(イテラブル)から新しいリストを生成するための、Python特有の簡潔な書き方です。 一言で言えば、リストを作るためのfor文を1行に凝縮したものだと考えてください。
通常、新しいリストを作るには3行から4行のコードが必要になりますが、内包表記を使えばそれをたった1行にまとめることができます。 単に短くなるだけでなく、Pythonという言語が目指す「簡潔で読みやすいコード」を体現する強力な武器となります。
なぜリスト内包表記を使うのか¶
コードが短くなることは嬉しいですが、それ以外にも大きなメリットがあります。 最も重要なのは、コードの意図が明確になることです。
通常のfor文では、ループの中で何が行われているかを1行ずつ読み解く必要があります。 一方で内包表記は「この条件で、こういうリストを作ります」という宣言的な書き方になるため、パッと見ただけで目的が伝わります。
また、技術的な側面で見ると、内包表記は通常のfor文よりも実行速度がわずかに速いという特徴もあります。 大量のデータを扱う際、この小さな差が積み重なってパフォーマンスに影響を与えることもあるのです。
従来の書き方との比較¶
具体的なメリットを理解するために、まずは従来の書き方(for文)と内包表記を並べて比較してみましょう。 例えば、0から4までの数字を2乗したリストを作りたい場合、これまでは以下のように書いていたはずです。
# 従来の書き方
numbers = []
for i in range(5):
numbers.append(i ** 2)
print(numbers) # [0, 1, 4, 9, 16]
これに対し、リスト内包表記を使うと驚くほどシンプルになります。 次のコードを見て、そのスッキリ感を味わってみてください。
# リスト内包表記
numbers = [i ** 2 for i in range(5)]
print(numbers) # [0, 1, 4, 9, 16]
どちらも結果は同じですが、後者の方が直感的だと思いませんか。 「iの2乗を、range(5)の各iについて実行し、リストにする」という流れが、ブラケットの中に集約されています。
リスト内包表記の基本構文を解剖する¶
リスト内包表記を自由自在に操るためには、その構造をパーツごとに理解しておく必要があります。
基本的には、[ 新しい要素 for 変数 in 元のリスト ] という形を基本形として覚えてください。
この構文は、パズルを組み立てるような感覚で理解していくのが近道です。 それぞれのパーツがどのような役割を持っているのか、詳しく見ていきましょう。
三つの主要なパーツ¶
リスト内包表記は、大きく分けて三つの要素から成り立っています。 一つ目は「何を入れるか」を決める式、二つ目は「繰り返しの変数」、三つ目は「繰り返しの対象」です。
これを意識してコードを読むと、どんなに複雑に見える内包表記でも構造が透けて見えるようになります。 以下の表に、それぞれのパーツの役割を整理しました。
| パーツ | 名称 | 役割 |
|---|---|---|
i ** 2 |
式(Expression) | 新しいリストに追加される値を計算・定義する |
for i |
イテレーション | 元のデータから一つずつ要素を取り出す変数 |
in range(5) |
イテラブル | ループの元となるリストや範囲 |
この基本構造さえ頭に入っていれば、あとは応用するだけです。 次は、この構造に「条件」を付け加える方法について解説していきます。
条件分岐(if)を組み合わせる¶
リスト内包表記の真価は、特定の条件に合う要素だけを抽出したい時に発揮されます。
構文の最後に if 条件式 を付け加えるだけで、フィルタリング機能を追加できるのです。
例えば、リストの中から偶数だけを取り出して新しいリストを作りたいケースを考えてみましょう。 これも通常のfor文で書くと4行ほど必要ですが、内包表記なら流れるように記述できます。
# 0から9のうち、偶数だけを抽出する
evens = [i for i in range(10) if i % 2 == 0]
print(evens) # [0, 2, 4, 6, 8]
このように、if を使うことで「全ての要素を処理する」のではなく「条件に合うものだけを拾う」という操作が可能になります。
データ分析やウェブスクレイピングなどで、特定のキーワードを含むデータだけを集めたい時などに非常に重宝します。
実務で使える内包表記の例¶
私が現場でコードを書く際、リスト内包表記は「ただの便利ツール」以上の存在です。 それは、複雑なデータ変換を「一筆書き」で表現するためのキャンバスのようなものです。
10年間のキャリアの中で、特に「これは便利だ」と感じた実践的なパターンをいくつか紹介します。 初心者の方がこれらを使いこなせるようになれば、周囲のエンジニアからも一目置かれるようになるでしょう。
文字列リストの一括加工¶
実務でよくあるのが、文字列のリストに対して一括で処理を行う場面です。 例えば、ユーザーが入力した名前のリストがあり、それらの前後にある不要な空白を取り除き、全て大文字にしたいとします。
raw_names = [" alice ", "bob", " charlie "]
# 前後の空白を除去(strip)し、大文字(upper)にする
clean_names = [name.strip().upper() for name in raw_names]
print(clean_names) # ['ALICE', 'BOB', 'CHARLIE']
これをfor文で書くと、一時的な変数を作ったりappendを繰り返したりと、コードが散らかりやすくなります。 内包表記なら、変換の意図(stripしてupperにする)がダイレクトに伝わりますね。
ファイル一覧のフィルタリング¶
特定の拡張子を持つファイルだけをリストアップする、といった処理も内包表記の得意分野です。
ファイル名のリストから、.py で終わるものだけを抽出するコードを見てみましょう。
files = ["main.py", "script.py", "data.csv", "style.css", "utils.py"]
python_files = [f for f in files if f.endswith(".py")]
print(python_files) # ['main.py', 'script.py', 'utils.py']
このように、メソッドと組み合わせることで、フィルタリングの精度を自在に高めることができます。 「対象となるリスト」に対して「どんなフィルターをかけるか」という思考の流れが、そのままコードに反映されているのが分かります。
【関連記事】綺麗なコードって何?初心者から一歩抜け出す「リーダブルコード」の3つの基本
複雑なデータの平坦化(ネストの解消)¶
少し高度なテクニックですが、二次元リスト(リストの中にリストがある状態)を一つのリストにまとめることもできます。 「平坦化(Flattening)」と呼ばれるこの処理は、内包表記の中でfor文を二回書くことで実現します。
matrix = [[1, 2], [3, 4], [5, 6]]
# 二次元リストを一次元に変換する
flat = [item for row in matrix for item in row]
print(flat) # [1, 2, 3, 4, 5, 6]
一見すると複雑に見えるかもしれませんが、左側の for から順番に読み解いていけば大丈夫です。
「まず行(row)を取り出し、その行の中から要素(item)を取り出す」という順番通りに並んでいます。
初心者が陥りやすい「可読性の罠」¶
リスト内包表記は非常に便利ですが、使いすぎると逆にコードを読みづらくしてしまうという側面もあります。 エンジニアの間では「ワンライナー(1行で書くこと)への執着」が裏目に出ることがよくあります。
私が後輩のコードをレビューする際、最も注意深くチェックするのは「その内包表記は、一瞬で意味が理解できるか」という点です。 ここでは、内包表記を使うべきではない、あるいは注意すべき場面についてお話しします。
長すぎる内包表記は悪¶
内包表記の中に、さらに複雑な計算式や三項演算子、重なったif文などを詰め込むのは避けるべきです。 1行が100文字を超えるような内包表記は、もはや「読みやすいコード」ではありません。
「1行で書けた!」という自己満足のために、他人の(あるいは未来の自分の)理解を妨げていないか自問自答してみてください。 コードは書く時間よりも、読まれる時間の方が圧倒的に長いのです。
# 悪い例:何をしているか一瞬で分からない
result = [f(x) if x > 10 else g(x) for x in data if h(x) and k(x)]
このような場合は、無理に1行にまとめず、通常のfor文を使ってステップごとに処理を書く方が賢明です。 「内包表記が使えるから使う」のではなく、「内包表記の方が分かりやすいから使う」という基準を持ちましょう。
三項演算子との組み合わせに注意¶
内包表記の中で if-else を使いたい場合、書き順が少し変わるため混乱する人が多いです。
「条件に合うものだけを抽出する」場合は最後の方に if を書きましたが、「条件によって値を変える」場合は最初の方に書きます。
# 値を変換するif-else(式として扱う)
# 偶数ならそのまま、奇数なら'ODD'にする
numbers = [i if i % 2 == 0 else 'ODD' for i in range(5)]
print(numbers) # [0, 'ODD', 2, 'ODD', 4]
この「ifの位置が変わるルール」は、初心者にとって非常に紛らわしいポイントです。 複雑な条件分岐が入るなら、関数を定義してその関数を内包表記の中で呼び出すといった工夫を検討してください。
内包表記とパフォーマンスの真実¶
「内包表記は速い」という話を聞いたことがあるかもしれません。 果たしてそれは本当なのか、そしてどの程度の違いがあるのか、気になりますよね。
結論から言うと、多くの場合において内包表記は通常の append を使ったループよりも高速です。
これは、Pythonの内部でリストを構築する際のオーバーヘッドが内包表記の方が少ないためです。
実行速度の比較¶
何万回、何十万回と繰り返される処理においては、この速度差が顕著になります。 単純なリスト作成において、for文と内包表記の速度差を比較したイメージを見てみましょう。
| 処理内容 | 手法 | 実行速度(イメージ) |
|---|---|---|
| リスト作成 | 通常のfor + append | 普通(関数の呼び出しコストがある) |
| リスト作成 | リスト内包表記 | 高速(内部で最適化されている) |
| リスト作成 | map関数 + list化 | 非常に高速(ただし可読性は内包表記に劣る場合も) |
ただし、現代のコンピュータは非常に高性能ですので、数百回程度のループであれば速度差は体感できません。 速度向上だけを目的に内包表記を導入するのではなく、あくまで「読みやすさ」を主軸に置くのがプロの考え方です。
【関連記事】「実行時間が終わらない…」を卒業する!あなたのコードを100倍速くする計算量の考え方
計算量の概念を理解しておくことは大切ですが、早すぎる最適化は諸刃の剣となります。 まずは「正しく、美しく書く」ことに集中し、パフォーマンスがボトルネックになった段階で速度を意識するのが良いでしょう。
メモリ消費の観点¶
リスト内包表記には、一つだけ弱点があります。 それは、「生成したリストを全てメモリ上に展開する」という点です。
例えば、1億個の要素を持つリストを内包表記で作ろうとすると、お使いのPCのメモリを一気に食い潰してしまう可能性があります。 このような巨大なデータを扱う場合は、リスト内包表記ではなく「ジェネレータ式」という別の記法を使うのが定石です。
ジェネレータ式は [] ではなく () で囲むだけで使えます。
これを使うと、要素を「その都度」生成するため、メモリを節約しながら巨大なループを回すことが可能になります。
さらなる応用:辞書内包表記と集合内包表記¶
リスト内包表記の便利さを知ると、他のデータ型でも同じようなことができないかと考えたくなりませんか。 嬉しいことに、Pythonには「辞書(dict)」や「集合(set)」を作るための内包表記も用意されています。
これらを使いこなせると、データ構造の変換がよりスムーズになります。 まずは、キーと値を同時に入れ替えるような「辞書内包表記」から見ていきましょう。
辞書内包表記の魔法¶
辞書内包表記は、{ キー: 値 for 変数 in イテラブル } という形で記述します。
例えば、リストにある単語をキーに、その文字数を値にした辞書を作りたい時に便利です。
words = ["apple", "orange", "banana"]
# 単語とその文字数を辞書にする
word_counts = {w: len(w) for w in words}
print(word_counts) # {'apple': 5, 'orange': 6, 'banana': 6}
これをfor文で書くと、辞書の初期化や代入で数行使ってしまいますが、これなら一瞬です。 データのマッピングや変換において、これほど強力な記法は他にありません。
集合内包表記で重複を取り除く¶
集合(set)を作る内包表記は、辞書と似ていますが「キーと値のペア」ではなく、単一の値を記述します。 集合の特徴である「重複を許さない」という性質を利用したい時に非常に有効です。
# 文字列のリストから、含まれる文字を(重複なく)抽出する
text = "abracadabra"
unique_chars = {char for char in text if char not in "abc"}
print(unique_chars) # {'d', 'r'}
リスト内包表記と書き方はほぼ同じですが、括弧が {} になっている点に注目してください。
用途に合わせて最適な内包表記を選べるようになると、Python中級者への道が開けます。
AIと歩むこれからのPython学習¶
2026年現在、GitHub CopilotやChatGPTといったAIツールが、私たちの代わりにコードを書いてくれるようになりました。 「内包表記なんて覚えなくても、AIが書いてくれるからいいや」と思うかもしれません。
しかし、現実はその逆です。 AIは非常に賢く内包表記を提案してきますが、そのコードが「本当に適切か」「可読性を損なっていないか」を判断するのは、人間にしかできません。
AIが提案するコードの「審美眼」を持つ¶
AIは時として、非常に凝った、しかし読みづらい内包表記を生成することがあります。 その時に、「これはかっこいいけど、後のメンテナンスが大変だからfor文に直そう」と判断できる力が、エンジニアの真の価値となります。
内包表記の仕組みを深く理解しているからこそ、AIを正しく使いこなすことができるのです。 便利なツールに振り回されるのではなく、自分の知識を土台にしてAIを強力なパートナーにしていきましょう。
継続的なアウトプットの重要性¶
今回学んだリスト内包表記を忘れないようにするための唯一の方法は、実際に自分のコードで使ってみることです。 今日書いたfor文の中に、内包表記に書き換えられる場所はありませんか。
学んだことをすぐに実践し、時には失敗してエラーを見る。 その繰り返しが、あなたを確かな実力を持つエンジニアへと成長させてくれます。
アウトプットの場として技術ブログを活用するのも良いです。 自分がどうやってリスト内包表記を克服したかを書くことで、同じように悩む誰かの助けになり、同時に自分自身の理解も深まります。
【関連記事】技術ブログを書くまでが学習!学んだことをアウトプットして市場価値を上げる方法
まとめ¶
Pythonの哲学の一つに「Simple is better than complex(単純であることは、複雑であることよりも良い)」という言葉があります。 リスト内包表記は、まさにこの哲学を体現した素晴らしい機能です。
しかし、シンプルさと「不親切な短さ」は紙一重です。 常に「このコードを読む人はどう思うか」という想像力を持ちながら、内包表記という強力な武器を振るってください。
あなたの書くコードが、昨日よりも少しだけ短く、そして圧倒的に美しくなることを願っています。 Pythonの世界は広く、まだまだ面白い機能がたくさんあります。
今回身につけた「リスト内包表記」という視点を持って、さらに深く理解しましょう!
ここまでお読みいただき、ありがとうございました。