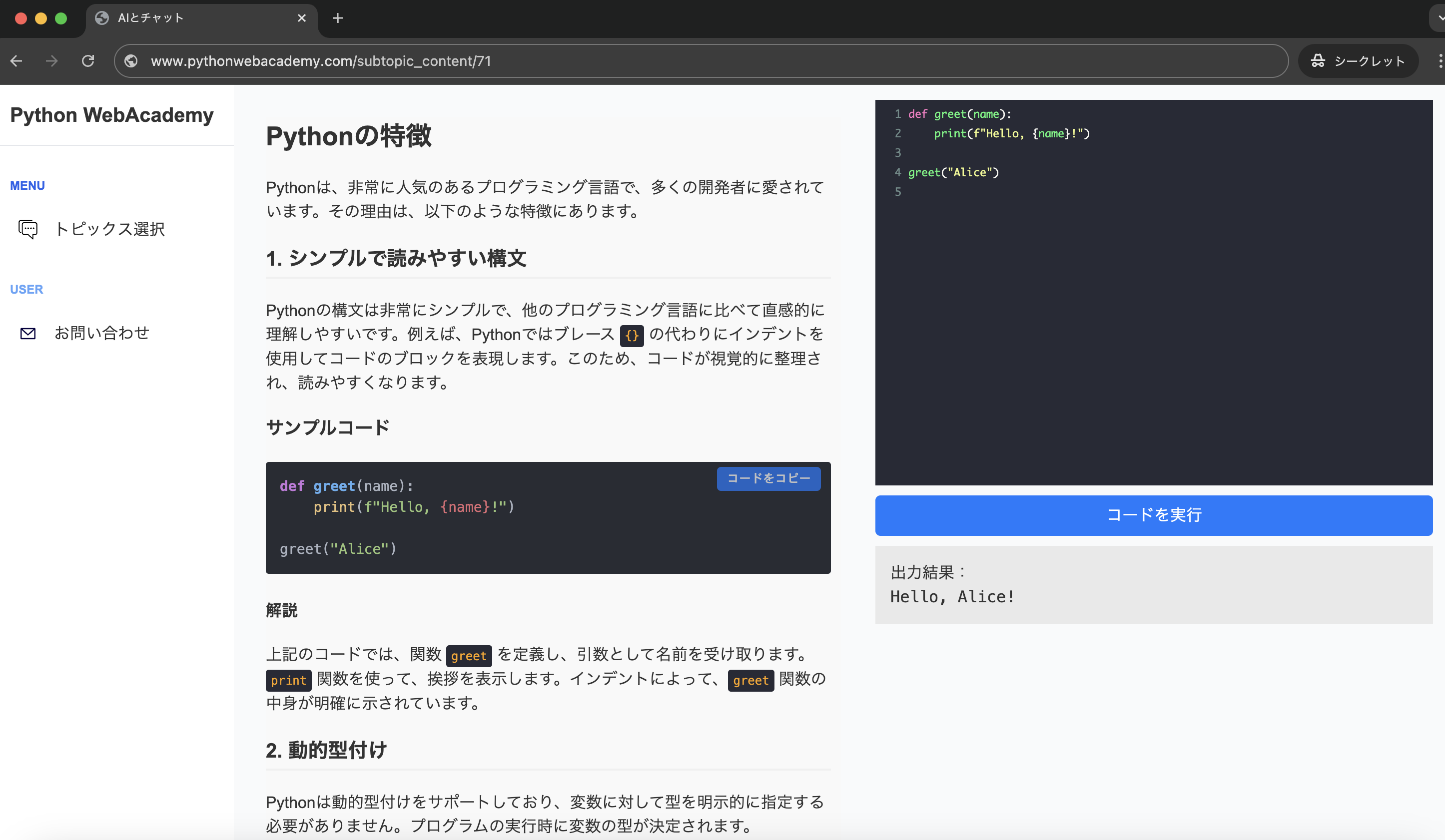
Pythonでリストやタプルの要素をループで処理しているとき、「今、何番目の要素を処理しているんだっけ?」と疑問に思うことはありませんか。
プログラミングを始めたばかりの頃、多くの人が直面するのがこのインデックスの管理という問題です。
一般的には、数え上げるための変数を用意して、ループの最後で1を足すという方法を思いつくかもしれません。 しかし、Pythonにはその作業を簡単に、そして読みやすく解決してくれるenumerate(イニュメレイト)関数が用意されています。
今回は、初心者の方が今日から使えるenumerate関数の基本から、現場で役立つちょっとした応用テクニックまでをじっくり解説していきます。
enumerate関数とは?なぜ必要なのか¶
まずは、この関数がなぜ存在するのか、その背景から紐解いていきましょう。 プログラミングにおける繰り返しの作業では、データそのものだけでなく「何番目か」という情報がセットで必要になる場面が驚くほど多いのです。
例えば、ランキングを表示したり、エラーが起きた行数を特定したりする場合です。 こうした場面で、Pythonが推奨する「最も美しい書き方」がenumerate関数を使う方法となります。
インデックス管理の「面倒くさい」を解決する¶
通常、インデックスを知りたい場合は、リストの長さを測って範囲を指定する手法がよく取られます。 しかし、その書き方だとコードが少し複雑になり、読み間違えの原因にもなりかねません。
# 昔ながらの、少し読みにくい書き方
fruits = ["apple", "banana", "orange"]
for i in range(len(fruits)):
print(i, fruits[i])
この「range(len(リスト))」という呪文のような書き方を卒業させてくれるのが、enumerate関数の役割です。 この関数は、リストの中身と一緒に、その番号をセットにして返してくれる親切な司書さんのような存在だと思ってください。
コードの「可読性」が上がる理由¶
読みやすいコードのことをリーダブルコードと呼びますが、enumerate関数を使うと、まさにその状態に近づけます。 なぜなら、変数に「今何番目か」と「中身は何か」を同時に、分かりやすい名前で割り当てることができるからです。
エンジニアの世界では、コードは書く時間よりも他人に読まれる時間の方が圧倒的に長いと言われています。 自分やチームメイトが後から見返したときに、一目で意味が伝わるコードを書くことは、プロへの第一歩なのです。
【関連記事】綺麗なコードって何?初心者から一歩抜け出す「リーダブルコード」の3つの基本
enumerate関数の基本的な使い方¶
それでは、実際にどのようにコードを書くのか、具体例を見ていきましょう。 基本の形は非常にシンプルで、for文の構成を少し変えるだけですぐに導入できます。
基本の構文と戻り値の仕組み¶
enumerate関数は、引数にリストなどの「並んだデータ」を渡すことで機能します。 すると、「(0, 要素1), (1, 要素2), ...」といったペアを順番に生成してくれるのです。
# enumerateを使ったスマートな書き方
items = ["Python", "Java", "C++"]
for i, name in enumerate(items):
print(f"{i}番目の言語は{name}です")
ここで重要なのが、i, nameという部分です。
これはアンパックと呼ばれる手法で、ペアになったデータを一度に2つの変数へ仕分けしています。
この書き方を覚えれば、わざわざitems[i]のようにインデックスを指定して中身を取り出す手間がなくなります。
コードが短くなるだけでなく、うっかり存在しないインデックスを指定してエラーを出してしまうリスクも減らせるのです。
内部で起きていることのイメージ¶
enumerateが何をしているのかを、もう少し詳しくイメージしてみましょう。 この関数は、単に番号を振るだけでなく、現在の位置を指し示しながらデータを1つずつ渡してくれます。
このイメージ図のように、データと番号がセットになって流れてくる様子を想像すると、理解が深まるはずです。 番号(インデックス)と実際の値が常にペアで動くため、管理ミスが起きにくい構造になっています。
range(len())との決定的な違い¶
初心者の方がよく使う「range(len(リスト))」という手法と、今回のenumerate。 どちらも同じ結果を得られますが、なぜプロの現場ではenumerateが好まれるのでしょうか。
その理由は意図の明確さと安全性にあります。 それぞれの特徴を比較してみましょう。
C言語スタイルか、Pythonスタイルか¶
range(len(リスト))という書き方は、もともとC言語やJavaなどの古いプログラミング言語のスタイルに近いものです。 一方で、enumerateは「Pythonらしさ(Pythonic)」を象徴する書き方だと言えます。
| 特徴 | range(len(obj)) | enumerate(obj) |
|---|---|---|
| 可読性 | 低い(何をしているか読み解く必要がある) | 高い(番号と値を扱うことが明白) |
| 安全性 | インデックス操作ミスでエラーが起きやすい | 値を直接扱うため安全 |
| 記述量 | 長くなりやすい | 短くスッキリ書ける |
| 用途 | インデックスだけが必要な特殊なケース | 番号と値の両方が必要なとき |
リストの中身を書き換えるのではなく、ただ読み取って何かをしたいだけであれば、enumerate一択です。 リストの要素を直接変数として扱えるため、コードの意図がボヤけずに済みます。
現場で起きたトラブルの例¶
以前、私が参加したプロジェクトで、range(len())を多用していたコードがありました。 複雑なループの中で、うっかりインデックスの変数を別の処理で書き換えてしまい、無限ループやエラーが頻発したのです。
enumerateに書き換えたところ、インデックスと値の関係が固定されたため、そうした人為的なミスは一切なくなりました。 ツールに任せられる部分はツールに任せる。これがバグを減らすための鉄則です。
【関連記事】100行のコードが10行に?Pythonic(パイソンらしい)な書き方への第一歩
番号を1から始めたいときの「start」引数¶
enumerate関数の隠れた名機能に、開始番号の指定があります。 プログラミングの世界は「0」から数え始めるのがルールですが、人間にとっては「1」からの方が自然ですよね。
例えば、ユーザー向けのメッセージを表示するときに0番目のアイテムと言うと、少し違和感があります。
そんなとき、多くの人はi + 1として調整しますが、enumerateならもっとスマートに解決できます。
start引数の使い方¶
enumerate関数の第2引数にstart=1と書き加えるだけで、開始番号を自由に変更できます。
わざわざループの中で計算を行う必要はありません。
# 1から数え上げたい場合
members = ["田中", "佐藤", "鈴木"]
for i, name in enumerate(members, start=1):
print(f"出席番号{i}: {name}さん")
# 出力結果: 出席番号1: 田中さん ...
このように、startという名前の通り、カウントの起点となる数字を指定できます。
もちろん、100から始めたいならstart=100とすればOKです。
読み手のストレスを減らす工夫¶
この機能を使うメリットは、コードの中に余計な「+1」という計算式が登場しなくなる点です。 「i + 1」と書いてあると、読み手は一瞬「なぜ1を足しているんだ?」と考える必要があります。
しかし、start=1と書いてあれば、誰が見ても「あ、このループは1から数えたいんだな」と直感的に理解できます。
こうした読み手の思考を止めない工夫の積み重ねが、良いエンジニアの条件です。
辞書や文字列、タプルでも使える柔軟性¶
enumerate関数が対応しているのは、リストだけではありません。 Pythonのイテラブル(繰り返し可能な)オブジェクトであれば、何にでも番号を振ることができます。
これが非常に強力で、文字列の1文字ずつに番号を振ったり、タプルの要素にインデックスを付けたりするのもお手の物です。 具体的にどのような使い道があるのか、いくつかの例を見ていきましょう。
文字列を1文字ずつ処理する¶
文字列も、実は文字が並んだデータとして扱えます。 何文字目に特定の文字があるかを探したり、加工したりするときに便利です。
text = "PYTHON"
for i, char in enumerate(text, start=1):
print(f"{i}文字目は {char} です")
このように、複雑な文字列解析のプログラムでもenumerateは大活躍します。 デバッグの際などに、今どの文字を読み取っているのかを表示させるのにも役立ちますね。
辞書(dict)で使う場合の注意点¶
辞書の場合は、そのまま渡すと「キー」に対して番号が振られます。 もし「値」も一緒に扱いたいなら、少し工夫が必要です。
scores = {"Math": 90, "English": 80}
# キーと番号を取得
for i, subject in enumerate(scores):
print(i, subject)
# キーと値の両方を扱いながら番号も振る
for i, (subject, score) in enumerate(scores.items()):
print(f"{i}: {subject}は{score}点")
辞書の.items()メソッドを組み合わせることで、さらに高度な繰り返し処理が可能になります。
少し複雑に見えるかもしれませんが、これも基本のペアを返してくれる司書さんという考え方は同じです。
リスト内包表記でenumerateを活用する¶
Pythonの中級者を目指すなら避けて通れないのがリスト内包表記です。 実は、この便利な書き方の中でもenumerateを使うことができます。
データの加工とフィルタリングを1行で行う際、インデックスの情報が欲しいことはよくあります。 どのように組み合わせるのか、その魔法のような記述を見てみましょう。
1行でインデックス付きのデータを作る¶
例えば、元のリストの要素を、インデックスと一緒に新しい形式に加工したい場合です。 通常なら数行かかる処理が、驚くほどスッキリまとまります。
fruits = ["apple", "banana", "cherry"]
# インデックス付きの文字列リストを作成
indexed_fruits = [f"{i}: {f}" for i, f in enumerate(fruits)]
print(indexed_fruits)
# ['0: apple', '1: banana', '2: cherry']
このように、内包表記の中でもfor i, f in enumerate(fruits)と書くだけでインデックスが利用可能になります。
これを知っていると、データの整形作業が非常にスピーディに行えるようになります。
特定の条件に合うインデックスを抽出する¶
「特定の条件を満たす要素の、インデックス(番号)だけが欲しい」というケースもあります。
内包表記の末尾にifを添えれば、フィルタリングも同時進行です。
scores = [50, 80, 45, 90, 70]
# 80点以上のデータの番号だけを抜き出す
high_score_indices = [i for i, s in enumerate(scores) if s >= 80]
「何番目のデータが条件に合致したか」を一瞬で特定できるこのテクニック。 実際のデータ分析の現場でも、欠かせない手法の一つとなっています。
【関連記事】Pythonのリスト内包表記を使いこなせ!3行のループを1行にまとめる書き方
enumerate関数は「重い」のか?パフォーマンスの真実¶
「便利なのは分かったけれど、わざわざ番号を振る処理を挟むと動作が遅くなるんじゃないの?」 そんな疑問を持つ方もいるかもしれません。
特に大量のデータを扱う場合、処理スピードは無視できない問題です。 しかし、安心してください。enumerate関数は驚くほど軽量に設計されています。
イテレータという「省エネ」な仕組み¶
前回のrange関数の記事でも触れましたが、enumerateも一度に全ての番号を作るわけではありません。 「次のデータが必要になった瞬間」にだけ、次の番号を生成して渡してくれます。
これを「遅延評価」や「イテレータ」と呼びますが、これによりメモリをほとんど消費しません。 100万個のリストを処理しても、一瞬で番号を生成してくれます。
実測値としてのパフォーマンス¶
エンジニア歴10年の感覚値として、手動でi += 1と足していく処理と、enumerateを使う処理で速度差を体感したことはありません。
むしろ、Python内部で最適化されているため、下手に自分でロジックを組むよりも高速に動作することさえあります。
「効率が良いから使う」のではなく、「読みやすくて、かつ効率も十分だから使う」のが正しいエンジニアの選択です。 スピードを気にして読みやすさを犠牲にする必要はありません。
反復処理メソッド比較まとめ¶
ここまで学んできたenumerateと、他の繰り返し手法を整理しておきましょう。 どの場面でどの道具を使うべきか、この表を見れば一目瞭然です。
| メソッド | 向いている場面 | 特徴 |
|---|---|---|
| for val in list | 値だけが必要なとき | 最もシンプルで基本の形 |
| for i, val in enumerate(list) | 値と番号の両方が必要なとき | Python推奨の最も美しい書き方 |
| range(len(list)) | インデックスで特殊な計算をするとき | リストの書き換えなどに限定すべき |
| zip(list1, list2) | 2つのリストを同時に回したいとき | インデックス管理なしで並列処理 |
| enumerate(zip(L1, L2)) | 複数リストと番号が必要なとき | 最強の組み合わせ技 |
このように、enumerateは「値と番号の両方」を扱う際の最強のカードです。 基本のfor文に慣れてきたら、次はこのカードをいつ切るかを意識してみてください。
実務でのアドバイス¶
最後に、現場でどのようにenumerateと向き合うべきか、私の考えをお伝えします。 技術は知っているだけではなく、どう使うかが重要です。
チーム開発での信頼につながる¶
あなたが書いたコードを、半年後の自分や、新しくチームに入った人が見るところを想像してください。
enumerateを使っているだけで、「この人はPythonの作法を分かっているな」という安心感を与えられます。
逆に、range(len())が並んでいるコードを見ると、プロのエンジニアは「この人は他の言語から来たばかりかな?」とか「基礎が抜けているかも」と警戒してしまいます。
コードはあなたの実力を雄弁に物語る「履歴書」なのです。
あえてenumerateを使わないケース¶
もちろん、何でもかんでもenumerateを使えば良いわけではありません。
例えば、リストの順番を逆から回したい場合(逆順ループ)などは、前回の記事で紹介したreversed(range())などの方が適切なこともあります。
「今、自分は何を一番に伝えたいのか(番号なのか、逆順なのか)」を考え、その意図に最も近い関数を選ぶ。 それができるようになると、あなたのプログラミングスキルは一段上のレベルに到達します。
【関連記事】pythonのrange関数の使い方は?ステップ指定と逆順ループの小技をご紹介!
まとめ¶
いかがでしたでしょうか。 enumerate関数は、一見地味ですが、Pythonの哲学である「シンプルで読みやすい」を体現した非常に重要な関数です。
開始番号を1にずらしたり、内包表記と組み合わせたりといったテクニックを覚えるだけで、あなたの書くコードは驚くほど洗練されたものに変わります。 「range(len())」からの卒業は、初級者から中級者へステップアップするための通過儀礼でもあります。
今日学んだことを、ぜひ今書いているプログラムの中に取り入れてみてください。 きっと、以前よりもコードを書くのが楽しくなり、自分のコードに自信が持てるようになるはずです。
ここまでお読みいただきありがとうございました。