あなたは数千行もあるテキストの中から、特定の形式のメールアドレスや電話番号だけをすべて探し出したいと思ったことはありませんか?
一つひとつ目視で探すのは気が遠くなりますし、単純な検索機能では「@が含まれる文字列」といった曖昧な条件を指定することはできません。
そんな時に真価を発揮するのが正規表現(Regular Expression)という技術です。 これを使えば、複雑なパターンの文字列を驚くほどシンプルに、そして一瞬で検索したり置換したりすることが可能になります。
私はエンジニアとして10年ほどコードを書いてきましたが、正規表現をマスターしたことで作業効率が100倍以上に跳ね上がった場面を何度も経験してきました。 今回は、初心者の方がつまずきやすいこの「呪文」のような記号の正体を、どこよりも分かりやすく丁寧に紐解いていきます。
1. そもそも正規表現とは何なのか?¶
正規表現とは、特定の文字の並び方を「パターン」として表現するための特別な記述方法のことです。 例えば「数字が3つ、ハイフン、数字が4つ」という規則性を、専用の記号を使って表現します。
プログラミング言語に依存しない共通の概念であり、Pythonはもちろん、JavaScriptやPHP、さらにはテキストエディタの検索機能でも利用できます。 一見すると暗号のように見えますが、ルールさえ知ってしまえばこれほど便利な道具は他にありません。
10年前の私が感じた「正規表現の恐怖」¶
私が新人エンジニアだった頃、先輩が書いた正規表現のコードを見て「これは人間が読むものではない」と本気で恐怖を感じたのを覚えています。 記号がびっしりと並んだその一行は、まるで魔法の呪文か、あるいはキーボードを適当に叩いた跡のようでした。
しかし、実際に使ってみるとその合理性に感動し、今では「正規表現なしのエンジニア人生は考えられない」と断言できるほど愛用しています。 あなたも最初は戸惑うかもしれませんが、この記事を読み終える頃にはその便利さに気づいているはずです。
2. 基本的な記号とその役割を知ろう¶
正規表現は、通常の文字と「メタ文字」と呼ばれる特別な意味を持つ記号を組み合わせて作ります。 まずは、これだけ覚えておけば日常的な作業の8割はカバーできるという主要な記号をご紹介します。
記号の意味を一つずつ理解していくことで、複雑なパターンの正体が見えてくるようになります。
文字の集合を表す記号¶
特定の文字そのものではなく「数字のどれか」や「英字のどれか」を指定したい時に使う記号です。 これらを使うことで、検索の幅を一気に広げることができます。
| 記号 | 意味 | 具体的な例 |
|---|---|---|
| . | 任意の1文字(何でも良い1文字) | a.c は abc や azc にマッチ |
| \d | 数字の1文字(0-9) | \d\d は 12 や 99 にマッチ |
| \w | 英数字とアンダースコア | \w\w は a1 や _b にマッチ |
| \s | 空白文字(スペースやタブ) | \s は半角スペースなどにマッチ |
| [abc] | aかbかcのいずれか1文字 | [p-z] はpからzまでのどれか |
つなぎとして、これらの記号を組み合わせることで、より具体的な条件を作ることが可能になります。
例えば、数字3文字を探したい場合は \d\d\d と書くだけで良いのです。
繰り返しの回数を指定する記号¶
同じ種類の文字が何回続くかを指定する記号を「量化子」と呼びます。 これを使うことで、文字数が決まっていないデータも柔軟に探せるようになります。
| 記号 | 意味 | 具体的な例 |
|---|---|---|
| * | 0回以上の繰り返し | a* は 「(なし)」や「aaaa」にマッチ |
| + | 1回以上の繰り返し | a+ は 「a」や「aaaa」にマッチ |
| ? | 0回または1回の出現 | https? は http と https の両方にマッチ |
| {n} | ちょうどn回の繰り返し | \d{3} は 123 など数字3桁にマッチ |
つなぎとして、例えば電話番号(090-0000-0000)を表現したいなら、\d{3}-\d{4}-\d{4} と書けば完璧です。
このように、規則性を記号に置き換えていく作業こそが正規表現の楽しさでもあります。
【関連記事】:Pythonのアンダーバー(アンダースコア)とはなんなのか?
3. Pythonで正規表現を使ってみよう¶
理屈がわかったところで、次は実際にPythonのコードを動かして正規表現の威力を体感してみましょう。
Pythonでは re という標準ライブラリを使用することで、簡単に正規表現を扱うことができます。
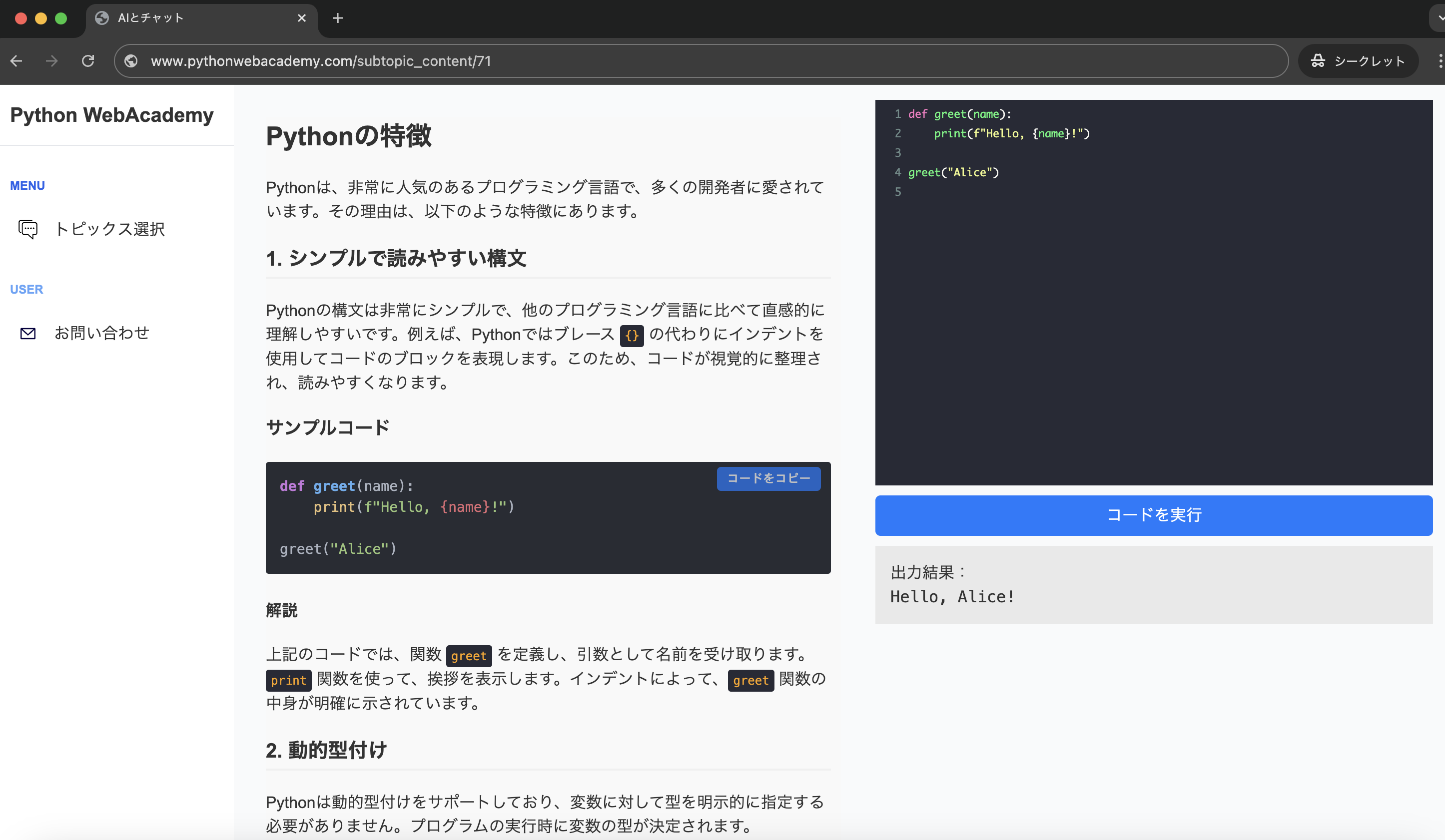
まずは、テキストの中からメールアドレスのような形式を探し出すサンプルをご紹介します。
import re
text = "お問い合わせは support@example.com または info@test.jp までお願いします。"
# メールアドレスのパターンを定義(簡易版)
# [a-zA-Z0-9._%+-]+ : 英数字や記号が1文字以上
# @ : アットマーク
# [a-zA-Z0-9.-]+ : ドメイン部分
# \.[a-zA-Z]{2,} : ドットと2文字以上の英字
pattern = r"[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}"
# 全て抽出
emails = re.findall(pattern, text)
print(f"見つかったメールアドレス: {emails}")
r"..." の意味を知っていますか?¶
コードの中で r という文字を文字列の前に付けていますが、これは「生文字列(raw string)」を意味します。
これを使わないと、バックスラッシュ(\)がPythonの特殊文字として解釈されてしまい、正規表現が正しく動かない原因になります。
エンジニア歴10年の私でも、たまにこの r を付け忘れて数分間悩むことがあるほど重要なポイントです。
正規表現を書くときは、おまじないのように r を付ける習慣をつけておきましょう。
置換機能でデータのクレンジングをする¶
検索だけでなく、特定のパターンの文字を一括で置き換える re.sub() も非常に強力です。
例えば、ログファイルに含まれる機密情報(電話番号など)を一括で伏せ字にする処理も一瞬で終わります。
import re
log_data = "ユーザーA: 090-1234-5678, ユーザーB: 080-9876-5432"
# 電話番号のパターンを探して「[SECRET]」に置き換える
cleaned_data = re.sub(r"\d{3}-\d{4}-\d{4}", "[SECRET]", log_data)
print(cleaned_data)
# 出力: ユーザーA: [SECRET], ユーザーB: [SECRET]
つなぎとして、数万件の顧客リストから個人情報を隠す必要がある場合、この数行のコードがあなたを救ってくれます。 手作業で行えば数日かかる仕事が、正規表現なら一秒もかからないのです。
4. 10年の現場経験から学ぶ「正規表現の勘所」¶
正規表現は強力ですが、使いこなすためにはいくつか意識すべきコツがあります。 これを知っているかどうかで、コードの品質とデバッグのしやすさが大きく変わります。
私がこれまでのキャリアで学んだ、実務で失敗しないためのアドバイスをお伝えします。
読みやすさを決して捨てない¶
正規表現は凝れば凝るほど複雑になり、書いた本人ですら翌日には理解できなくなる「書き捨て」のコードになりがちです。 あまりに複雑なパターンを書くときは、コメントを添えるか、処理を分割することを検討してください。
「動くからいい」ではなく「後から読む人が理解できるか」という視点を持つことが、プロのエンジニアへの近道です。 複雑すぎる正規表現は、将来のあなたへの嫌がらせになってしまう可能性があるからです。
外部ツールで試行錯誤する¶
いきなりPythonのコードの中に正規表現を書き始めるのは、実はあまり効率的ではありません。 世の中には、入力したテキストに対して正規表現がどうマッチするかをリアルタイムで視覚化してくれるツールがあります。
私は Regex101 などのオンラインツールを常に開きながら、パターンの調整を行っています。 こうしたツールを活用することで、凡ミスを防ぎ、より確実に目的のパターンを作り上げることができます。
【関連記事】:綺麗なコードって何?初心者から一歩抜け出す「リーダブルコード」の3つの基本
5. 欲張りなマッチに注意せよ(Greedy vs Non-greedy)¶
正規表現を学び始めると必ずと言っていいほど直面するのが、マッチする範囲が広すぎてしまう問題です。 これを理解していないと、思い通りの検索ができずに時間を浪費してしまいます。
デフォルトは「欲張り」である¶
例えば、<div>タグの中身</div> というテキストから <div> だけを取り出したいとします。
ここで <.*> というパターンを使うと、正規表現は「一番後ろの > 」まで探してしまい、テキスト全体にマッチしてしまいます。
import re
html = "<div>こんにちは</div>"
# 欲張りなマッチ(デフォルト)
print(re.findall(r"<.*>", html))
# 出力: ['<div>こんにちは</div>']
「おしとやか」に探す方法¶
必要な範囲だけを最小限にマッチさせるには、記号の後に ? を付けます。
これを「非強欲(ノン・グリーディ)マッチ」と呼びます。
# おしとやかなマッチ(最短一致)
print(re.findall(r"<.*?>", html))
# 出力: ['<div>', '</div>']
つなぎとして、この ? 一つの有無で結果が180度変わってしまいます。
HTMLタグの解析や、特定の記号で囲まれた部分を抜き出すときは、このテクニックが必須になります。
6. AI時代における正規表現との付き合い方¶
2026年現在、ChatGPTなどのAIを使えば、どんなに複雑な正規表現も一瞬で生成してくれます。 「AIが作ってくれるなら、自分で覚える必要はないのでは?」と思うかもしれません。
しかし、AIが出力した正規表現が「本当に正しいのか」を検証できる力がなければ、非常に危険です。 AIは稀に、特定の入力パターンに対して動作が著しく遅くなる「正規表現の脆弱性」を孕んだコードを出すことがあります。
処理が終わらなくなる「Catastrophic Backtracking」¶
正規表現の書き方によっては、マッチの組み合わせが爆発的に増え、CPUを100%占有してフリーズさせてしまう現象が起きます。 これを「破滅的なバックトラッキング」と呼びます。
AIが提案したコードをそのまま本番環境に組み込む前に、論理的に問題がないかを見抜く審美眼が必要です。 基礎を理解しているからこそ、AIという強力な相棒を安全に乗りこなすことができるのです。
【関連記事】:AIが提案するコード、信じていい? AIのミスを見抜くための審美眼
7. まとめ:正規表現を味方につけてエンジニアの翼を広げよう¶
正規表現は、一度身につけてしまえばプログラミング以外の場面でもあなたを助けてくれる一生モノのスキルです。 大量のログ解析、名簿の整理、ソースコードの一括修正など、その活用範囲は無限大です。
- 基本記号(\d, \w, .)を組み合わせてパターンを作る。
- 量化子(+, *, {n})で繰り返しの回数を指定する。
- Pythonのreモジュールを使って検索や置換を自動化する。
- 非強欲マッチ(?)を使いこなし、正確な範囲を指定する。
最初は記号の羅列に圧倒されるかもしれませんが、まずは簡単な数字の検索から始めてみてください。 自分の書いたパターンがピタリと目的の文字に重なった瞬間の快感は、パズルを解いた時の喜びにも似ています。
あなたが正規表現という「魔法の杖」を手に入れ、日々の退屈な作業を一瞬で終わらせられるようになることを願っています。 小さな成功体験を積み重ねて、一歩ずつプロの思考へ近づいていきましょう!
ここまでお読みいただきありがとうございました。