Pythonを学び始めてしばらく経つと、少しずつ扱うデータの量が増えてきますよね。 そんな時、プログラムが急に重くなったり、メモリ不足で止まってしまったりすることはありませんか。
実は、多くの初心者がぶつかるこの壁をスマートに解決してくれるのが、ジェネレータという仕組みです。 私はエンジニアとして10年ほどコードを書いてきましたが、このジェネレータは大規模なシステム開発には欠かせない必須ツールだと言い切れます。
今回は、不思議なキーワードであるyield(イールド)の正体と、その圧倒的なメリットを初心者の方にも分かりやすく解説します。
この記事を読み終える頃には、あなたの書くコードはよりプロフェッショナルで、効率的なものに進化しているはずです。
なぜ今、ジェネレータが必要なのか?¶
皆さんは、100万行ある巨大なCSVファイルを読み込んで、1行ずつ処理するプログラムを書こうとしたことはありますか。 もし全てのデータを一度にリストへ格納しようとすると、PCのメモリは一瞬で悲鳴を上げてしまいます。
プログラミングの世界では、メモリの節約は非常に重要なテーマです。 データが小さいときは気になりませんが、実務では数ギガバイトという膨大なデータを扱うことも珍しくありません。
メモリ不足の恐怖と戦うために¶
一度に全てのデータを読み込む方法は、たとえるなら100人分の料理を一度にテーブルに並べるようなものです。 テーブルが小さければ料理は乗り切りませんし、食べ終わる前に冷めてしまうかもしれません。
一方でジェネレータは、注文が入るたびに1皿ずつ料理を作って出す、カウンター形式のレストランのようなものです。 これならテーブルが小さくても、何百人ものお客さんに料理を提供し続けることができますよね。
もしコードの書き方に迷いがあるなら、まずは「読みやすさ」の基本を振り返ってみるのも良いかもしれません。
【関連記事】:綺麗なコードって何?初心者から一歩抜け出す「リーダブルコード」の3つの基本
リストとジェネレータの決定的な違い¶
まずは、私たちが普段よく使うリストと、今回の主役であるジェネレータを比較してみましょう。
この2つの違いを理解することが、yieldを使いこなすための第一歩となります。
基本的な考え方の違いを、以下の表にまとめてみました。
| 特徴 | リスト(List) | ジェネレータ(Generator) |
|---|---|---|
| データの持ち方 | 全ての結果を一度にメモリに保存する | 必要なときに1つずつデータを生成する |
| メモリ消費量 | データ量に比例して増える(大) | 常に一定(極小) |
| 実行のタイミング | 呼び出された瞬間に全ての計算を終える | データが必要になるまで計算を遅らせる |
| アクセス方法 | インデックス([0]など)で自由にアクセス可 | 先頭から順番にしか取り出せない |
リストは「全件買取」、ジェネレータは「都度生産」¶
リストは、全てのデータをあらかじめ用意して箱に詰め込んでおくイメージです。 どこからでも好きなデータを取り出せる便利さはありますが、箱のサイズ(メモリ)を圧迫してしまいます。
ジェネレータは、その場で作って、その場で渡すという動きをします。 一度渡したデータは忘れてしまうため、メモリをほとんど使わずに無限に近いデータでも扱えるのが最大の強みです。
この「必要なときだけ計算する」という考え方は、アルゴリズムの効率化にも直結します。 【関連記事】:「実行時間が終わらない…」を卒業する!あなたのコードを100倍速くする計算量の考え方
yieldの魔法:関数を一時停止させる技術¶
ジェネレータを作るために使うのが、yieldというキーワードです。
通常の関数で使うreturnと似ていますが、その動きは全く異なります。
returnは、値を返した瞬間にその関数を完全に終了させてしまいます。
しかし、yieldは値を返した後に、その場所で処理を一時停止し、関数の状態を保存しておくのです。
yieldの動きを追いかけてみよう¶
具体的なコードで、yieldがどのように動くのかを見てみましょう。
一見すると普通の関数に見えますが、呼び出し方に特徴があります。
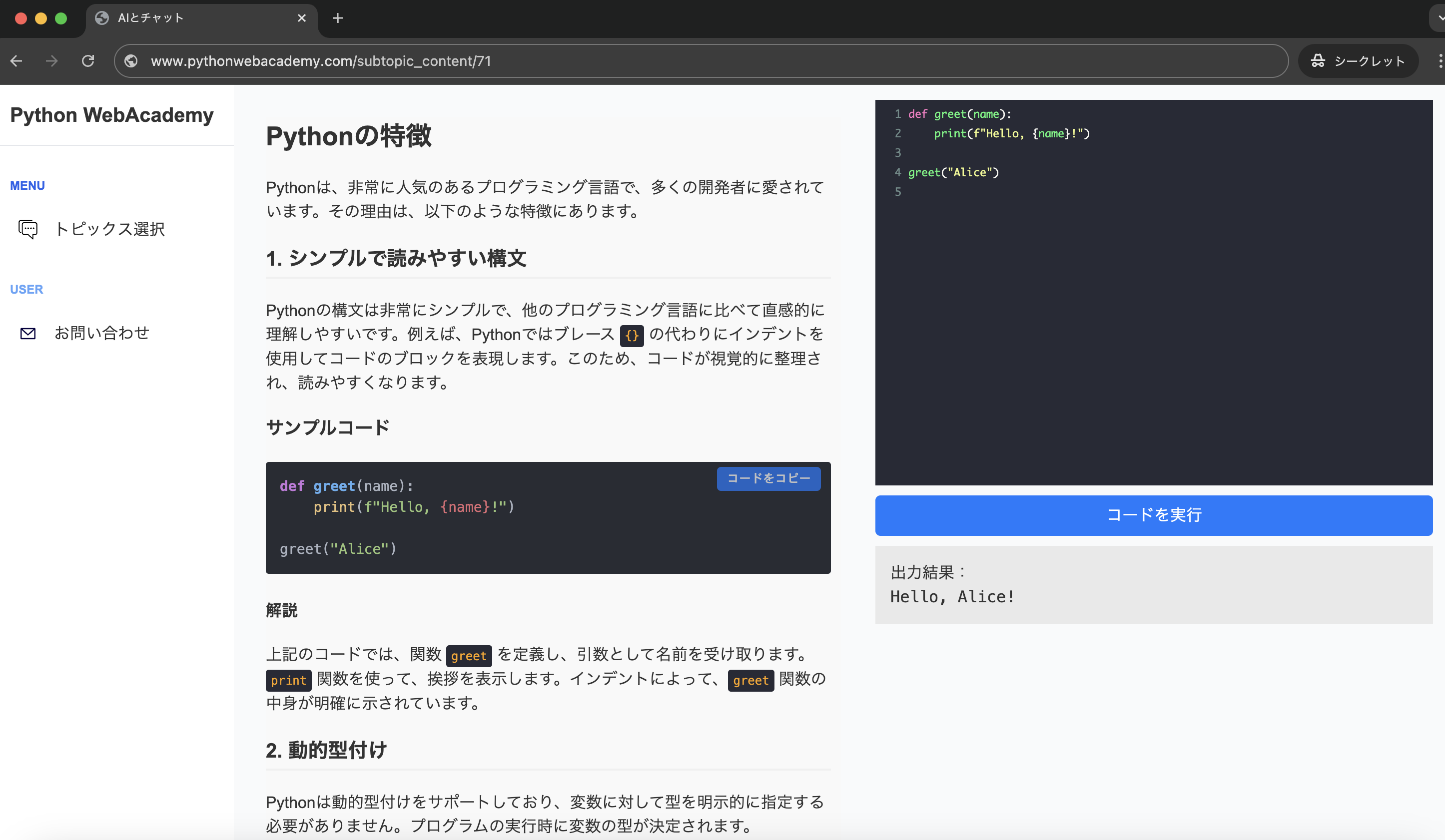
def count_up():
print("1つ目を出します")
yield 1
print("2つ目を出します")
yield 2
print("3つ目を出します")
yield 3
# ジェネレータオブジェクトの作成
g = count_up()
print(next(g)) # 1を返して停止
print(next(g)) # 2を返して停止
print(next(g)) # 3を返して終了
このコードを実行すると、next()を呼び出すたびに、前回の続きから処理が再開されるのが分かります。
関数が自分の仕事をどこまでやったか覚えている、というのは非常に面白い性質だと思いませんか。
10年の経験で学んだ、ジェネレータを使うべき3つの場面¶
エンジニアとして10年働いてきた中で、私が「ここは絶対にジェネレータだ」と判断するポイントがいくつかあります。 初心者の方にも分かりやすい、代表的な3つのケースをご紹介します。
これを意識するだけで、あなたのプログラムのパフォーマンスは劇的に向上するでしょう。
1. 数GBの巨大なテキストファイルを読み込むとき¶
ログファイルや巨大なデータセットを扱う際、f.readlines()を使ってはいけません。
全ての行をリストにしてしまうため、ファイルのサイズと同じだけのメモリを消費してしまうからです。
代わりに、ファイルオブジェクト自体が持つジェネレータ機能や、yieldを使った行読み込みを活用します。
これなら、10GBのファイルであっても数MBのメモリでサクサクと処理することが可能です。
2. 無限に続くデータを扱うとき¶
例えば、特定の規則に従って永遠に数字を生成し続けるような処理は、リストでは作れません。 リストは「終わり」がないと、メモリが溢れてクラッシュしてしまうからです。
ジェネレータなら、次に必要な値だけをその都度計算するため、無限ループのような構造でも安全に扱えます。 必要な分だけ取り出して、満足したら処理を打ち切る、といった柔軟なプログラミングが可能になります。
3. 重い処理を分割して実行したいとき¶
1つの大きな処理を一度に行うと、その間画面がフリーズしたり、他の処理が止まったりします。 ジェネレータを使えば、処理の合間に「休憩(一時停止)」を挟むことができます。
これにより、ユーザーの操作を受け付けながらバックグラウンドで少しずつ計算を進める、といった工夫ができるようになります。 システムのレスポンスを良くするためにも、非常に有効なテクニックです。
さらに高度なループ処理を行いたい場合は、標準ライブラリの活用も検討してみてください。 【関連記事】:itertoolsを使いこなせ!複雑なループ処理を1行で美しく書くテクニック
サンプルコードで学ぶ、yieldの基本と応用¶
それでは、実際にジェネレータを使った便利なプログラムを書いてみましょう。 ここでは、大量のデータを加工して出力する、実務でもよくあるパターンを例にします。
まずは、1から100万までの数字を2乗して返す処理を、リストとジェネレータで比較してみます。
import sys
# リストで作る場合
def square_list(n):
result = []
for i in range(n):
result.append(i * i)
return result
# ジェネレータで作る場合
def square_gen(n):
for i in range(n):
yield i * i
# 100万件で比較
n = 1000000
my_list = square_list(n)
my_gen = square_gen(n)
print(f"リストのメモリサイズ: {sys.getsizeof(my_list)} バイト")
print(f"ジェネレータのメモリサイズ: {sys.getsizeof(my_gen)} バイト")
メモリ消費量の差に注目¶
このコードを実行すると、リストは数メガバイトのメモリを消費するのに対し、ジェネレータはわずか数十バイトしか使いません。 データ件数が1000万、1億と増えても、ジェネレータのメモリ使用量は変わらないのです。
「データが増えても重くならないコード」というのは、プロの開発現場で非常に高く評価されるポイントです。 小さな工夫ですが、これができるかどうかが初心者と中級者の大きな分かれ道になります。
ジェネレータを使うときに注意したい落とし穴¶
とても便利なジェネレータですが、使いこなすには注意点も知っておく必要があります。 私が後輩エンジニアのコードをレビューする際にも、よく指摘するポイントを2つお伝えしますね。
これを知っておかないと、「なぜかデータが空になっている」というバグに悩まされることになります。
1. 一度使い切ると、空になる¶
ジェネレータは、一度最後までデータを出し切ると、二度と同じデータを取り出すことはできません。 再びデータが欲しい場合は、もう一度ジェネレータオブジェクトを生成し直す必要があります。
リストのように「何度も使い回す」ということができないため、設計段階で注意が必要です。 統計計算などで同じデータを何度もループさせる場合は、一度リストに変換するか、生成し直す仕組みを作りましょう。
2. インデックスで直接アクセスできない¶
ジェネレータに対して g[5] のように特定の順番のデータを指定して取得することはできません。
あくまで「次のデータは?」と聞き続けることしかできないのです。
もし特定の要素だけが欲しいのであれば、最初からリストを使うか、enumerateなどを組み合わせて順番を数える必要があります。
適材適所、という言葉通りですね。
まとめ¶
今回は、Pythonの強力な機能であるジェネレータとyieldについて詳しく解説しました。
「メモリを節約する」「必要なときだけ作る」という考え方は、モダンなプログラミングにおいて非常に大切です。
最初は少し難しく感じるかもしれませんが、自分でコードを書いて動かしてみるのが一番の近道です。 まずは、簡単な数値の生成から始めて、徐々に大きなファイルの読み込みなどに応用してみてください。
プログラミングの学習は、こうした小さな発見の積み重ねです。 自分のコードが以前より効率的に動くようになったときの喜びを、ぜひ大切にしてください。
ここまでお読みいただきありがとうございます。