あなたが書いたPythonのコードが、実際に画面に文字を出したり、計算を行ったりする瞬間を想像してみてください。 キーボードで打ち込んだ英単語のような文字が、どうしてコンピュータという機械を動かせるのでしょうか?
多くのプログラミング初学者は、コードを書いて実行ボタンを押すだけで満足してしまいがちです。 しかし、そのボタンの裏側では、目にも止まらぬ速さで複雑な「翻訳作業」が行われています。
この仕組みを理解することは、単なる好奇心を満たすだけではありません。 エラーの原因を突き止めたり、より高速で効率的なプログラムを書いたりするための確固たる基礎となります。
今回は、Pythonがソースコードを読み込んでから実行するまでの内部プロセスを、IT初心者の方でもイメージしやすいように解説していきます。
Pythonは「通訳」を介して動く言語¶
プログラミング言語には、大きく分けてコンパイル言語とインタプリタ言語の2種類が存在します。
Pythonは後者のインタプリタ言語に分類されますが、これは一体どういう意味なのでしょうか。
コンピュータの脳であるCPUは、実は私たちが書くPythonのコードを直接理解することはできません。 CPUが理解できるのは「0」と「1」だけで構成されたマシン語(機械語)という極めてシンプルな命令だけです。
人間とコンピュータの橋渡し役¶
私たちが書くPythonのコードを、コンピュータが理解できるマシン語にリアルタイムで翻訳してくれるのがインタプリタです。 これを料理に例えるなら、レシピ(ソースコード)を見ながらその場で調理を進める料理人のような存在と言えるでしょう。
あらかじめ全ての命令を翻訳しておく必要がないため、コードを書いてすぐに実行できるという手軽さがあります。 この手軽さこそが、Pythonが初心者にとって親しみやすい最大の理由のひとつとなっています。
【関連記事】Pythonはなぜ“インタプリタ言語”なのか?インタプリタ言語とは何なのか解説!
コンパイル言語との決定的な違い¶
対照的な存在であるコンパイル言語(C言語やGoなど)は、実行前に全てのコードを一括で翻訳します。 これは、外国語の本をあらかじめ全て日本語に翻訳してから出版するようなイメージです。
事前の翻訳作業に時間はかかりますが、いざ読む(実行する)ときは翻訳の手間がないため非常に高速です。 Pythonは実行のたびに翻訳を行うため、一般的にはコンパイル言語よりも実行速度が遅くなる傾向にあります。
実行までの3つのステップ¶
Pythonの実行ボタンを押してから結果が出るまで、内部では大きく分けて3つの工程が進んでいます。 単に1行ずつ読んでいるだけではなく、実は途中で「中間形態」に変身しているのが面白いポイントです。
それでは、具体的にどのようなステップを踏んでプログラムが変換されていくのか見ていきましょう。
ステップ1:ソースコードの解析とバイトコードへの変換¶
まずは、あなたが作成した .py ファイルをPythonが読み込みます。
ここで最初に行われるのは、人間向けの言葉をもう少しコンピュータに近い「中間的な言葉」に変える作業です。
この中間的な言葉のことを、専門用語で バイトコード と呼びます。 バイトコードは人間が読むことは難しいですが、マシン語ほど単純すぎない、Python専用の命令セットです。
この変換プロセスをコンパイルと呼びますが、Pythonの場合は自動で行われるため、私たちが意識することはありません。
よく見かける __pycache__ というフォルダの中にある .pyc ファイルの正体が、このバイトコードなのです。
ステップ2:Python仮想マシン(PVM)による実行¶
次に登場するのが、Python仮想マシン(PVM) と呼ばれるソフトウェアです。 先ほど生成されたバイトコードを、このPVMが1つずつ読み取って実行していきます。
PVMはいわば、Python専用の「仮想的なコンピュータ」のような役割を果たします。 バイトコードをOS(WindowsやMacなど)に合わせた命令に最終翻訳し、実際のハードウェアに伝えます。
この「仮想マシン」というクッションを挟むことで、PythonはどんなOSでも同じように動くことができます。 一度書いたコードがどこでも動く仕組みは、このPVMのおかげなのです。
ステップ3:OSとハードウェアへの命令¶
最終的に、PVMからの命令がOSを通じてCPUやメモリに届きます。 ここでようやく、メモリにデータが保存されたり、画面に計算結果が表示されたりといった物理的な変化が起こります。
あなたが print("Hello") と書いた一行は、この長い旅を経てようやくディスプレイに光を灯すのです。
こうして見ると、たった1つの命令を動かすために、背後で多くのシステムが連携していることがわかりますね。
なぜPythonは「遅い」と言われるのか?¶
プログラミングを学んでいると、Pythonは他の言語に比べて遅いという話を耳にすることがあるかもしれません。 それは、今説明した「仮想マシンを介した逐次翻訳」という仕組み自体に理由があります。
しかし、2026年現在のPythonは、かつてほど遅い言語ではなくなってきています。 開発チームの多大な努力により、内部的な実行効率はバージョンを追うごとに劇的に改善されているからです。
【関連記事】Pythonは本当に遅い?初心者にもわかる原因と対処法を徹底解説
GIL(グローバルインタプリタロック)の存在¶
Pythonの実行速度を語る上で避けて通れないのが、GIL(グローバルインタプリタロック) という仕組みです。 これは、複数の処理を同時に行おうとしても、一度に1つのスレッドしかPythonのバイトコードを実行できないという制限です。
この制限がある理由は、データの整合性を守り、メモリ管理を安全に行うためです。 初心者の方には少し難しい話ですが、この安全第一の設計が、時として計算速度のボトルネックになることがあります。
逐次実行によるオーバーヘッド¶
インタプリタが1行ずつコードを解釈して動かす際、どうしても「解釈の時間」というコストが発生します。 一気に翻訳を済ませるコンパイル言語に比べれば、このオーバーヘッドは無視できない差になります。
ただし、近年のPython 3.11や3.12、さらには最新の3.14といったバージョンでは、この翻訳効率が大幅に強化されました。 今では、多くの用途において速度の差を感じることは少なくなっています。
仕組みを知るメリット¶
私がエンジニアとして活動してきた中で、この実行の仕組みを知っていて本当に良かったと思う瞬間が何度もありました。 それは、単にコードを書けるだけではなく、「なぜ動かないのか」を深く理解する助けになったからです。
特に大規模なデータを扱うプロジェクトや、AIの学習モデルを構築する際には、この知識が不可欠です。
メモリ管理とパフォーマンスの最適化¶
Pythonは、使わなくなったメモリを自動で回収してくれる ガベージコレクション という機能を備えています。 しかし、この仕組みを知らないと、意図せず大量のメモリを消費し続けるコードを書いてしまうことがあります。
実行の裏側を知っていれば、どのように変数を定義すれば効率的かを肌感覚で理解できるようになります。 「なんとなく書く」から「意図を持って書く」への変化は、プロフェッショナルへの第一歩です。
エラーメッセージが怖くなくなる¶
エラーが発生したとき、Pythonは「どのステップで問題が起きたか」を教えてくれます。 構文エラー(SyntaxError)であれば、ステップ1の解析段階でつまづいていることがわかります。
実行時エラー(RuntimeError)であれば、ステップ2のPVMが動いている最中に予期せぬことが起きた証拠です。 このように問題の所在を切り分けられるようになると、デバッグのスピードは飛躍的に向上します。
言語ごとの実行方式の比較¶
ここで、Pythonと他の主要なプログラミング言語の実行方式を比較してみましょう。 それぞれの言語が、どのタイミングで翻訳を行っているのかを整理しました。
| 言語 | 実行方式 | 翻訳タイミング | 特徴 |
|---|---|---|---|
| Python | インタプリタ方式 | 実行時に1行ずつ | 開発しやすく、修正が容易 |
| C++ | コンパイル方式 | 実行前に一括 | 実行速度が極めて高速 |
| Java | 中間コード方式 | コンパイル + 仮想マシン | 高速さとポータビリティを両立 |
| JavaScript | JITコンパイル方式 | 実行直前に最適化 | ブラウザ上で高速に動作 |
このように見ると、Pythonは「人間にとっての使いやすさ」に大きく舵を切った言語であることがわかります。 速度よりも開発効率を重視する現代のソフトウェア開発において、この選択は非常に理にかなっています。
実際に裏側を見てみよう¶
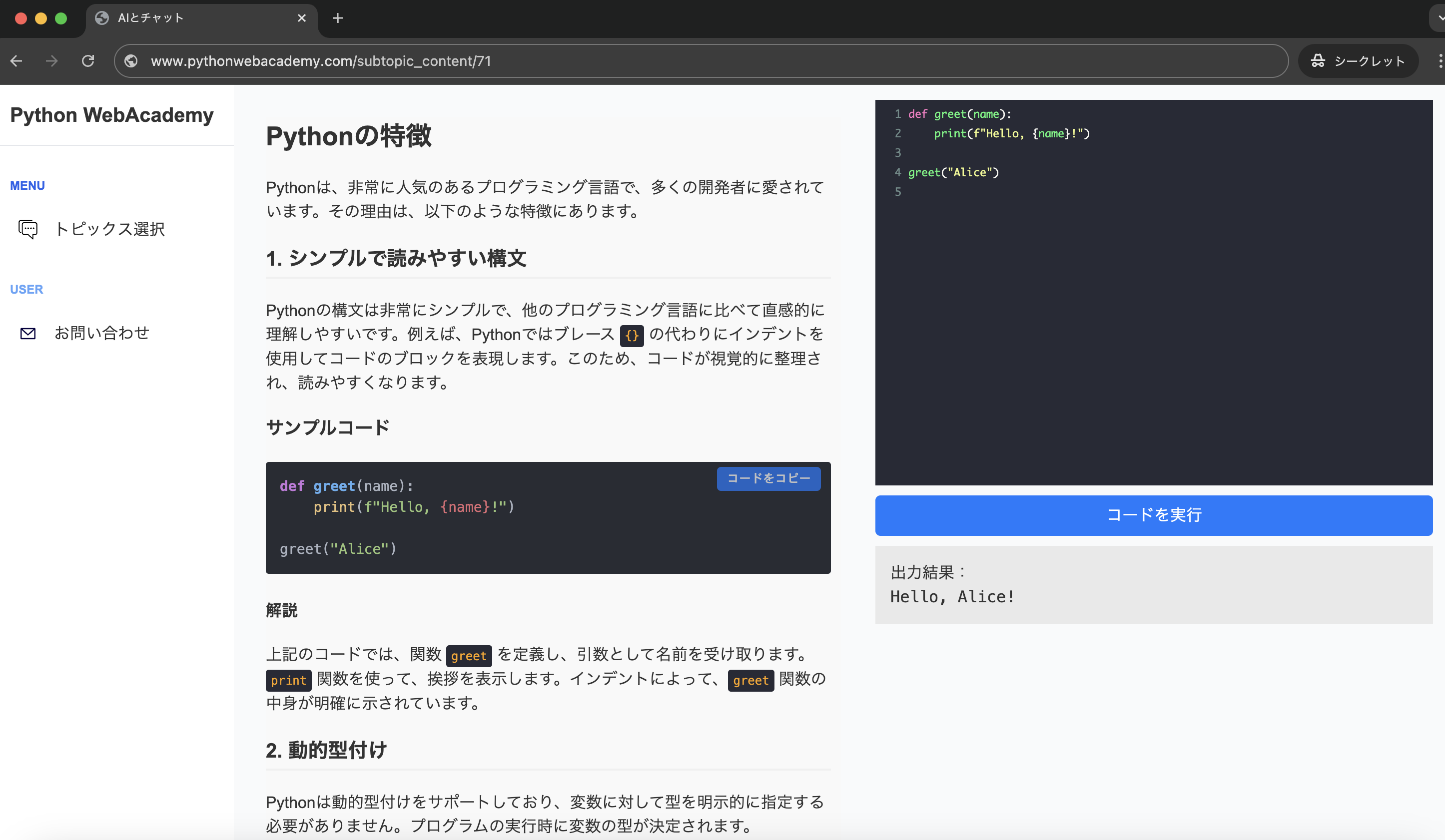
理屈ばかりでは退屈ですので、実際にPythonが生成しているバイトコードを少しだけ覗いてみましょう。
Pythonには dis モジュールという、コードを分解して表示してくれる標準ライブラリがあります。
これを使うと、あなたが書いた1行が、どのように細かな命令に分かれているかが一目瞭然です。
import dis
def add_numbers(a, b):
return a + b
# 関数のバイトコードを表示
dis.dis(add_numbers)
このコードを実行すると、画面には BINARY_ADD といった、見慣れない命令がいくつか表示されるはずです。
これが、先ほど説明した「ステップ1」で生成されるバイトコードの正体です。
人間が書いた + という記号が、PVMへの具体的な加算命令に変わっている様子が確認できますね。
こうした実験をしてみると、プログラミングが決して魔法ではなく、緻密な手順の積み重ねであることが実感できるでしょう。
仕組みを知ることで変わるコードの書き方¶
最後に、実行の仕組みを意識した、より良いコードを書くためのヒントをお伝えします。 Pythonの特性を活かすことで、初心者でも「プロっぽい」効率的なプログラムが書けるようになります。
まずは、Pythonの 標準ライブラリ や組み込み関数を積極的に使うことから始めてみてください。
標準ライブラリは「高速なC言語」で書かれている¶
Pythonの標準関数の多くは、実は内部で高速なC言語によって実装されています。 自分で複雑なループ処理を書くよりも、組み込み関数を1つ使うほうが遥かに速く動くことが多いのです。
これは、PVMがバイトコードを1つずつ解釈する手間を省き、一気に最適化された処理に飛び込めるからです。 「車輪の再発明をせず、既存のツールを賢く使う」ことは、Pythonにおいて非常に重要なテクニックです。
インデントが実行効率に与える影響¶
Pythonの大きな特徴であるインデントも、実は実行の仕組みと密接に関係しています。 解析ステップにおいて、インデントはコードの構造を決定する重要な目印となります。
綺麗に整えられたインデントは、人間にとって読みやすいだけでなく、Pythonがコードを解析する際の助けにもなります。 美しいコードを書く習慣は、エラーの混入を防ぐ最強の防御策であることを忘れないでください。
【関連記事】Pythonのインデント文化はどのように誕生したか?なぜPythonはインデントなのか解説
まとめ¶
Pythonの実行プロセスの旅、いかがでしたでしょうか? 普段私たちが何気なく使っているツールの裏側には、何十年にもわたるエンジニアたちの知恵が詰まっています。
全ての仕組みを完璧に覚える必要はありません。 ただ、「自分の書いた文字が、誰かの手によって翻訳され、マシンを動かしている」という感覚を持つだけで十分です。
その感覚こそが、ただの「コーダー」ではなく、システムを理解する「エンジニア」への境界線となります。 エラーに出会ったときも、この記事で学んだ3つのステップを思い出してみてください。
どこでバグが起きているのかを想像する力があれば、解決の糸口は必ず見つかります。 Pythonは、あなたの好奇心に応えてくれる、深く、そして楽しい言語です。
これからも、コードの表面だけでなく、その奥に広がる広大な仕組みの世界を楽しんでいきましょう。
ここまでお読みいただきありがとうございました。